








































































Fachmagazin für Pharmazie
Ich habe noch kein Benutzerkonto und möchte mich kostenlos registrieren.
Zur Registrierung
Künstliche Intelligenz (KI) ist einer der wesentlichen Treiber von Innovationen im Pharmabereich im 21. Jahrhundert. Unzählige Medikamente werden mithilfe von KI entdeckt, und so gut wie alle großen pharmazeutischen Unternehmen nützen KI zur Erforschung neuer Wirkstoffe. Im Zuge der COVID-19-Pandemie explodierten die privaten Investitionen im Bereich von Medikamenten und Medikamentenentwicklung von ca. 3 Mrd. US-Dollar auf 13,8 Mrd. Dollar.2 Unternehmen der pharmazeutischen und biotechnologischen Industrie geben typischerweise mehr als 1 Mrd. Dollar aus, bevor ein Wirkstoff auf den Markt kommt. Dieser Prozess kann dabei 10–15 Jahre dauern. Noch dazu werden 90% aller Kandidaten im Verlauf des Prozesses aufgrund von Wirksamkeits- oder Sicherheitsbedenken ausgeschieden.3 Es besteht also ein riesiges Potenzial zur Reduktion dieser Gesamtkosten. Gleichzeitig laufen Unternehmen, die heute keine KI zur Entwicklung oder Umwidmung (Repurposing) von Medikamenten nützen, Gefahr, den Anschluss zu verlieren.
Doch welche Einsatzgebiete gibt es für KI, maschinelles Lernen (Machine Learning – ML) und Deep Learning (DL), um neue Wirkstoffkandidaten schneller und günstiger zu identifizieren?
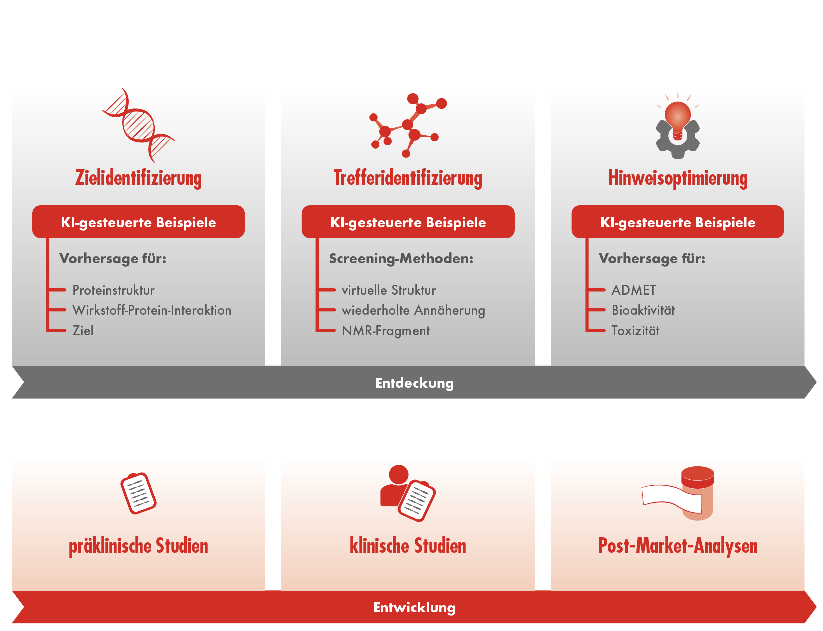
Am Anfang des Suchprozesses nach neuen Medikamenten steht die Identifikation eines geeigneten biologischen Angriffspunktes. KI kann hier Vorhersagen zu einem geeigneten Ziel, einer möglichen Proteinstruktur und der Wirkstoff-Protein-Interaktion treffen. Um daraus mögliche molekulare Treffer zu identifizieren, stehen verschiedene KI-gestützte Screening-Methoden zur Verfügung. Diese können entweder auf der virtuellen Struktur, einem NMR-Fragment oder auf wiederholter Annäherung basieren. Zuletzt müssen die gefundenen Kandidaten optimiert werden. KI kann dazu Prognosen hinsichtlich Absorption, Distribution, Metabolismus, Exkretion und Toxizität (ADMET) sowie Bioaktivität liefern.
Allein dieser erste Prozessabschnitt in der Entdeckung eines Medikaments noch vor der eigentlichen Entwicklungsphase mit präklinischen Studien, klinischen Studien und Post-Market-Analysen kann fünf oder mehr Jahre in Anspruch nehmen. Mithilfe von KI kann diese Zeit auf einige Monate verkürzt werden (Abb.).3, 4
Damit solche Fortschritte möglich sind, benötigen Firmen aber nicht nur eine ausreichende Menge an Daten, sondern auch eine ausreichende Qualität dieser Daten. Wie nützlich die vorhandenen Datensets sind, kann anhand einiger Kriterien bestimmt werden. Die der KI zugrunde liegenden Daten sollten eine hohe Abdeckung und eine hohe Konsistenz aufweisen, also alle relevanten (medizinischen) Informationen enthalten und einheitlich formatiert eingegeben werden. Neu hinzugefügte Daten sollten sich außerdem auf bereits vorhandene Datensätze beziehen. So können Verbindungen zwischen Datenpunkten geschaffen werden und die wechselseitige Kompatibilität der Datensets kann verbessert werden. Hierarchische, strukturierte und flexible Daten bedeuten, dass sie möglichst viele nachvollziehbare Levels an Details enthalten und je nach Bedarf nach den verschiedenen Schichten gefiltert, gesucht und bearbeitet werden können.
Wenn die Daten evidenzbasiert sind und die Herkunft zurückverfolgt werden kann, können sie angepasst werden, wenn sich die Evidenz dazu ändert. Qualitativ hochwertige Daten weisen schließlich auch die entsprechenden Metadaten auf, damit die Datenpflege (Hinzufügen, Aktualisieren etc.) transparent und optimierbar bleibt.4
Um neue, medizinisch nutzbare Biologika mithilfe von KI zu entdecken, können natürliche Proteine gentechnisch modifiziert werden (Protein-Engineering). Dazu werden KI-Algorithmen mit Labormethoden kombiniert mit dem Ziel, Biologika im Hinblick auf einen ungedeckten medizinischen Bedarf zu verbessern oder neu zu entwickeln. Neue Wirkstoffkandidaten können auf diese Weise viel schneller und in viel größerer Anzahl identifiziert, getestet und optimiert werden, als dies mit traditionellen Laboransätzen möglich wäre. Mit den heute verfügbaren Möglichkeiten kann die Struktur von Proteinen/therapeutisch genützten Antikörpern vorhergesagt werden, die Stabilität und die Halbwertszeit können verbessert (nötige Infusionsfrequenz) sowie die Proteinlöslichkeit und -aggregation verändert werden (Verabreichung). Über die Bindungsaffinität und Bindungsspezifität können Effektivität und Nebenwirkungen verbessert werden. Oft wird die Anwendbarkeit von Antikörpern zudem aufgrund einer ausgelösten Immunantwort begrenzt. Über ML können die immunogenen Untereinheiten identifiziert und auf Mutationen gescreent werden, die die Funktion und Stabilität der Proteine beibehalten, aber keine Immunantwort auslösen. Erst dann werden die entsprechenden Lösungen im Labor umgesetzt.5
Die benötigten strukturellen Daten stammen häufig von der Protein Data Bank, einer Open-Access-Datenbank, die (Stand Mai 2022) mehr als 190.000 Proteinstrukturen enthält.6 Große Technologieunternehmen wie Google und Facebook haben DL-Software entwickelt, um 3-D-Strukturen von Proteinen anhand der Sequenz zu berechnen. Teilweise sind diese sogar als Open Source verfügbar.
Künstliche Intelligenz in der Medikamentenforschung ist längst keine Zukunftsmusik mehr, sondern ein Milliardengeschäft für Pharmafirmen. Ihr Einsatz kann die langwierige Suche nach neuen Wirkstoffen sowohl verkürzen als auch effizienter machen, also mehr Treffer mit höheren Erfolgschancen liefern. Besonders Biologika sind naheliegende Einsatzgebiete von KI, da hier das Zusammenspiel aus Struktur, Stabilität und Funktion noch komplexer ist als bei kleinen Molekülen.
Was ist künstliche Intelligenz?
Eine einheitliche, allumfassende Definition für künstliche Intelligenz (KI; auch artifizielle Intelligenz – AI) ist schwer zu bestimmen. KI kann als der Versuch, klassische menschliche kognitive Funktionen sowie darauf basierende Entscheidungsabläufe auf maschinelle und computerisierte Systeme zu übertragen, beschrieben werden. Als der kleinste gemeinsame Nenner für die Definition von KI gelten die maschinelle Lernfähigkeit, also das permanente Ansammeln von Wissen und Erfahrungen, das fortwährende Erkennen von Wirkungszusammenhängen sowie das Ableiten und Aufbereiten von Erkenntnissen daraus.
Was ist maschinelles Lernen?
Unter maschinellem Lernen/Machine Learning (ML) wird üblicherweise die Fähigkeit eines Systems verstanden, automatisch zu lernen, ohne dabei fest auf die Ergebnisausgabe programmiert zu sein. Die Erkenntniszuwächse werden also eigenständig aus der Identifizierung von Mustern erzielt, ohne auf ein menschlich vorgegebenes, statisches Regelwerk zurückzugreifen oder einfach einzelne Elemente auswendig zu lernen.
Was ist Deep Learning?
Deep Learning (DL) kann als spezifische Methode des maschinellen Lernens verstanden werden. Es beruht meist auf der Verwendung von künstlichen neuronalen Netzwerken und greift dabei auf eine Vielzahl von maschinellen Lernalgorithmen zurück. Ein typisches künstliches neuronales Netzwerk besteht aus einer Vielzahl von Knotenpunkten, die – ähnlich wie natürliche Synapsen – Informationen zwischen den einzelnen Neuronen übermitteln. Deep Learning zeichnet sich dadurch aus, dass es eine lange Kette zusammenhängender Verbindungen – von Knotenpunkt zu Knotenpunkt – abbilden kann.1


Quelle: Firmen-Webinar von Deep Genomics: Improving the discovery of novel drugs with artificial intelligence, 3. 2. 2022
Vorschaubild: shutterstock_1108832840_sdecoret